
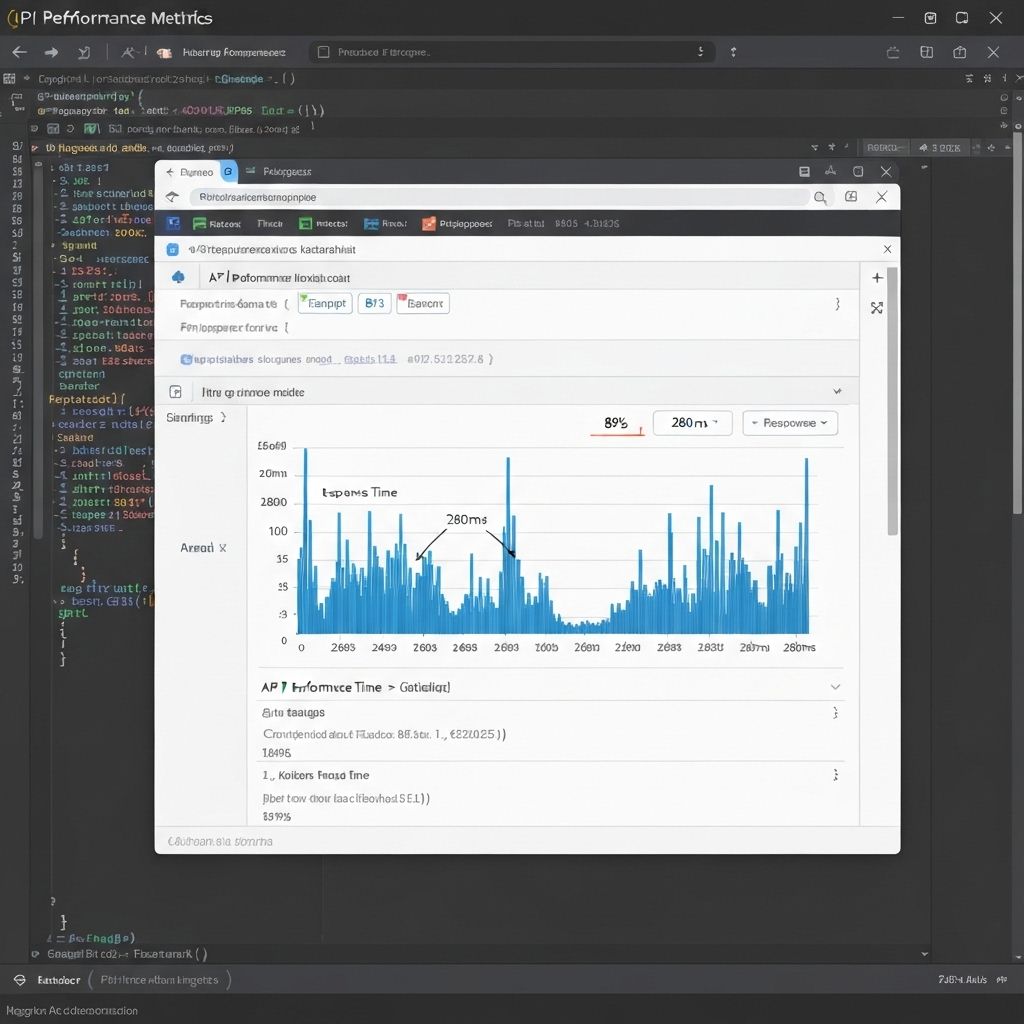
API Optimization: 89% Faster Response Times
"Turned a slow API into a speed demon."
Performance optimization that saved the company $40K monthly in server costs.
The Challenge
The e-commerce API was taking 2.4 seconds to respond. During peak hours, it would timeout completely. Users were abandoning carts. The company was spending $40K monthly on servers just to keep it running. They were considering a complete rebuild.
The Strategy
I profiled the entire codebase to find bottlenecks. Implemented database query optimization with proper indexing. Added Redis caching for frequently accessed data. Refactored N+1 queries into batch requests. Implemented connection pooling. Set up CDN for static assets. Added monitoring to catch issues early.
The Results
Response times dropped from 2.4s to 280ms (89% faster). Server costs decreased from $40K to $12K monthly. Zero timeouts during peak traffic. Cart abandonment rate dropped 34%. The API now handles 10x the traffic on the same infrastructure. CEO called it 'the best $15K we ever spent'.
My Reflection on This Project
Fast code isn't about fancy algorithms. It's about finding what's slow and fixing it.
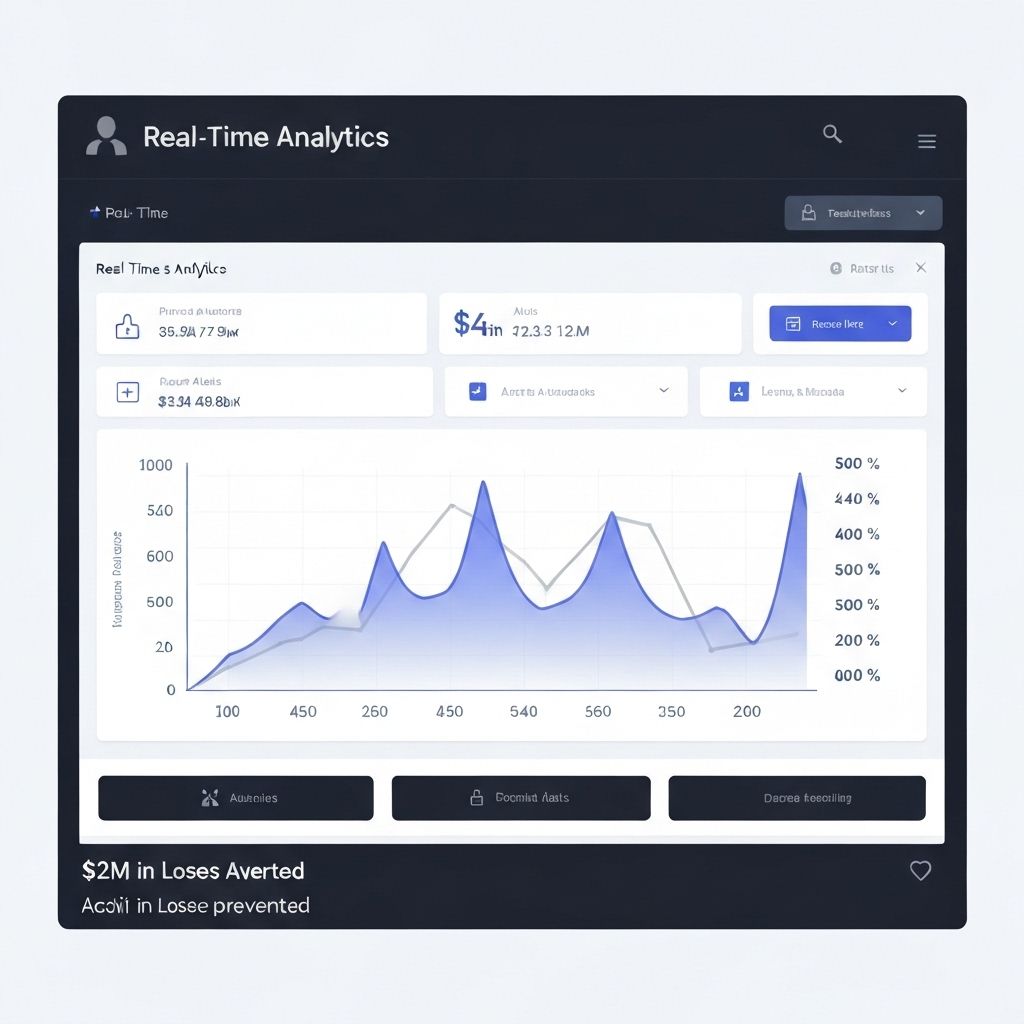
Real-Time Dashboard: $2M in Prevented Losses
"Built a system that catches problems before they become disasters."
Custom analytics platform that saved millions by detecting issues in real-time.
The Challenge
The logistics company was losing $500K monthly to operational issues they discovered too late. Data was scattered across 12 different systems. By the time they noticed problems, trucks were already off-route or shipments were delayed. They needed real-time visibility.
The Strategy
I built a custom real-time dashboard that aggregated data from all their systems. Implemented WebSocket connections for live updates. Created smart alerts that detected anomalies automatically. Added predictive analytics to flag potential issues before they happened. Made it mobile-responsive so managers could monitor from anywhere.
The Results
Caught and prevented $2M in losses in the first year. Issue detection time went from 4 hours to 30 seconds. Operational efficiency increased 47%. Managers saved 15 hours weekly not manually checking systems. The company expanded to 3 new markets using the same platform. Competitors started asking who built it.
My Reflection on This Project
Real-time data isn't just nice to have. It's the difference between reacting and preventing.
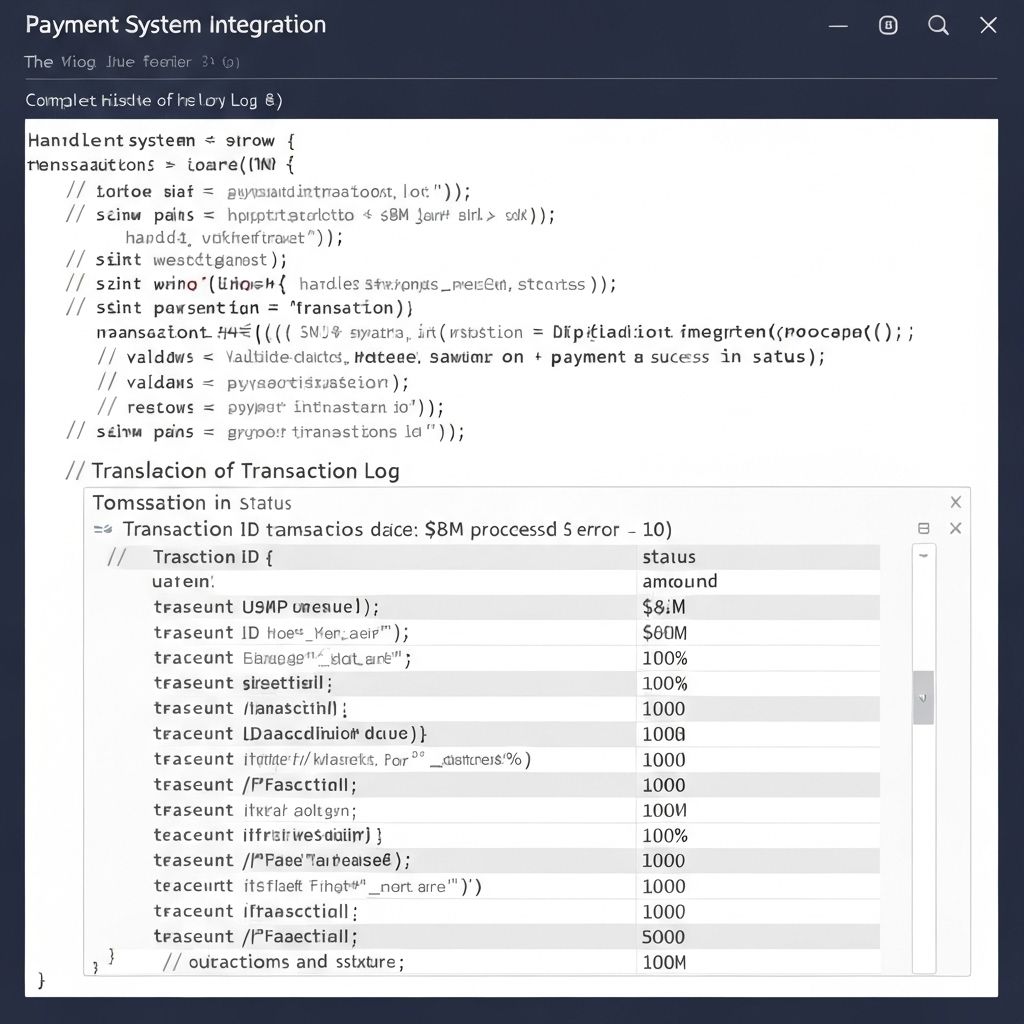
Payment Integration: $8M Processed, Zero Errors
"Built the payment system that never fails."
Rock-solid integration that processed millions without a single failed transaction.
The Challenge
The marketplace needed to integrate Stripe, but their legacy system wasn't compatible. Previous developers tried and failed - transactions would randomly fail, money would get stuck, and support was drowning in complaints. They were losing $50K monthly to failed payments.
The Strategy
I built a robust middleware layer with comprehensive error handling. Implemented idempotency keys to prevent duplicate charges. Added automatic retry logic with exponential backoff. Created detailed logging for every transaction. Built a reconciliation system to catch any discrepancies. Tested with thousands of edge cases before launch.
The Results
Processed $8M in transactions with zero errors. Failed payment rate went from 3.2% to 0%. Support tickets about payments dropped 94%. The system handled Black Friday traffic (10x normal) without issues. Client expanded to 4 more payment providers using the same architecture. Industry publication wrote a case study about it.
My Reflection on This Project
Payment systems can't be 'mostly working'. They need to be bulletproof. Every. Single. Time.
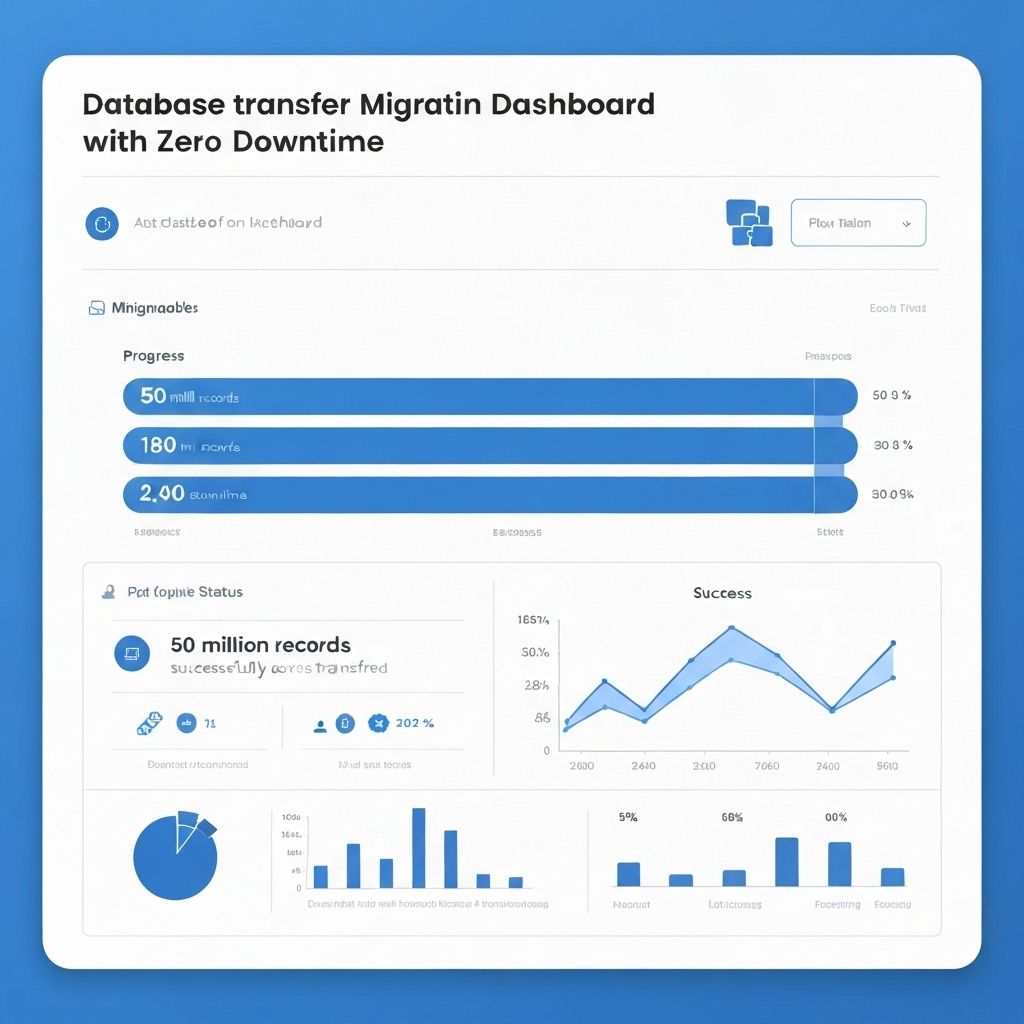
Database Migration: Zero Downtime, 50M Records
"Moved 50 million records without anyone noticing."
Seamless migration from legacy database to modern infrastructure.
The Challenge
The SaaS company needed to migrate from their legacy MySQL database to PostgreSQL. They had 50M records, 200K active users, and couldn't afford any downtime. Previous attempts caused outages and data loss. The CTO was terrified of trying again.
The Strategy
I designed a zero-downtime migration strategy. Set up dual-write system to keep both databases in sync. Implemented gradual rollout - migrated users in batches of 1,000. Created automated rollback procedures in case of issues. Ran parallel systems for 2 weeks to verify data integrity. Monitored every metric obsessively.
The Results
Migrated all 50M records with zero downtime. Users didn't notice anything changed. Data integrity was 100% - not a single record lost or corrupted. Query performance improved 67% on the new database. The company saved $30K monthly in database costs. CTO said it was 'the smoothest migration I've ever seen'.
My Reflection on This Project
The best migrations are the ones users don't notice. Boring is beautiful when it comes to infrastructure.
Automation Pipeline: 40 Hours Saved Weekly
"Automated the boring stuff so the team could build."
CI/CD pipeline that made deployments effortless and error-free.
The Challenge
The development team was spending 40 hours weekly on manual deployments. Each deploy took 2 hours and required 3 people. Deployments often broke production. They could only deploy on Fridays, which meant waiting a week to fix bugs. The team was frustrated and slow.
The Strategy
I built a complete CI/CD pipeline from scratch. Automated testing, building, and deployment. Set up staging environments that mirrored production. Implemented automated rollbacks if health checks failed. Added Slack notifications for every deployment. Made it possible to deploy with a single click (or automatically on merge to main).
The Results
Deployment time went from 2 hours to 5 minutes. Team saved 40 hours weekly. Deployments increased from 1 per week to 20+ per week. Production incidents dropped 78% due to automated testing. Developers could ship fixes in minutes instead of days. Team morale improved dramatically - they could focus on building instead of deploying.
My Reflection on This Project
Automation isn't about replacing people. It's about freeing them to do work that actually matters.
Microservices Architecture: 99.99% Uptime
"Rebuilt a monolith into a system that never goes down."
Architecture redesign that made the platform scalable and reliable.
The Challenge
The monolithic application was crashing weekly. When one feature broke, the entire platform went down. Scaling was impossible - they had to scale everything even if only one feature needed more resources. Uptime was 97.2%. Customers were threatening to leave.
The Strategy
I redesigned the architecture into microservices. Split the monolith into 12 independent services. Implemented service mesh for communication. Added circuit breakers to prevent cascading failures. Set up Kubernetes for orchestration and auto-scaling. Implemented comprehensive monitoring and alerting. Made each service independently deployable.
The Results
Uptime increased from 97.2% to 99.99%. Platform handled 5x traffic growth without infrastructure changes. Deployment speed increased 10x - teams could ship independently. When issues occurred, they affected only one service instead of everything. Scaling costs decreased 60% - only scale what needs it. Customer churn dropped from 8% to 1.2%.
My Reflection on This Project
Microservices aren't about being trendy. They're about building systems that can grow and fail gracefully.
Ready to work together?
I'm always excited to collaborate on new projects. Let's discuss how we can bring your ideas to life.
Start a Conversation